The Boring Stuff
Last updated: April 02, 2026

When you describe what a coding agent harness does, background daemons, multi-agent coordination, session memory, skill injection, mesh networking, it sounds like Pepe Silvia. But underneath all of it, the primitives are boring: files on a filesystem, shell commands, API calls, markdown documents. There is no magic runtime. No hidden orchestration layer. Just tools doing predictable things.
That is the point. Years ago, Automate the Boring Stuff made the case that programming is most useful when it handles the tedious parts of your work. This is the same idea, applied one level up: the harness automates the boring parts of using an AI coding agent. Not the thinking. Not the judgment calls. The filing, the conventions, the context recovery, the verification. The stuff that is not fully deterministic, but teachable.
Things the agent can learn from a skill, recover from with the right tools, or figure out given enough context. Not trivial automation, but not hard judgment either. The boring middle.
The best example is convention enforcement. Early on, repos kept getting cloned to wrong paths. After the third time, I updated the git skill with a references/REPO-LAYOUT.md documenting the convention: workspace/code/{git-server}/{org}/{repo}. Pi injects skill descriptions into the system prompt, which makes the model proactively load the git skill before any git operation. Just saying "follow this convention" in a skill is sometimes enough. That class of mistake stopped happening.
The boring part: following the convention, every time, without thinking about it. The hard part: recognizing the pattern after three failures. Deciding to encode it. Writing a convention clear enough that an LLM interprets it correctly.
The harness enforces this through skill loading. When the agent runs a bash command with git in it, Pi's keyword matching triggers the git skill. The skill says "repos go here." The agent follows it. You could even enforce this more strictly: require that the git skill be loaded in context before any git bash call is allowed. That's a reasonable TODO.
Same pattern with code verification. I once spawned two agents against git history and the codebase to verify claims in a wiki document. They found wrong dates, inflated numbers, and a timeline that didn't match the commit log. Reported back through inter-agent messaging while I kept working on something else. This started because we'd caught a NATS client bug in the zero-agent repo through exactly this kind of cross-referencing: checking what the code actually said against what the docs claimed.
The boring part: digging through git history, cross-referencing commit dates, counting things. The hard part: deciding which claims needed verification and knowing what to do with the discrepancies.
Handoffs are another instance. When I run /handoff, the daemon analyzes the session and fills in context: key discoveries, decisions made, files modified, what's left. Next session, /pickup loads it. The agent has the full picture without re-reading conversation history.
The boring part: extracting decisions from a long session, tracking what changed, structuring next steps. The hard part: making the architectural calls in the first place.
Each of these follows the same pattern. The agent handles what's mechanical. I handle what requires judgment. The investment pays off when the time saved applies to every future session.
The pattern: attention is the scarce resource, not code. That's what the loop is built around.
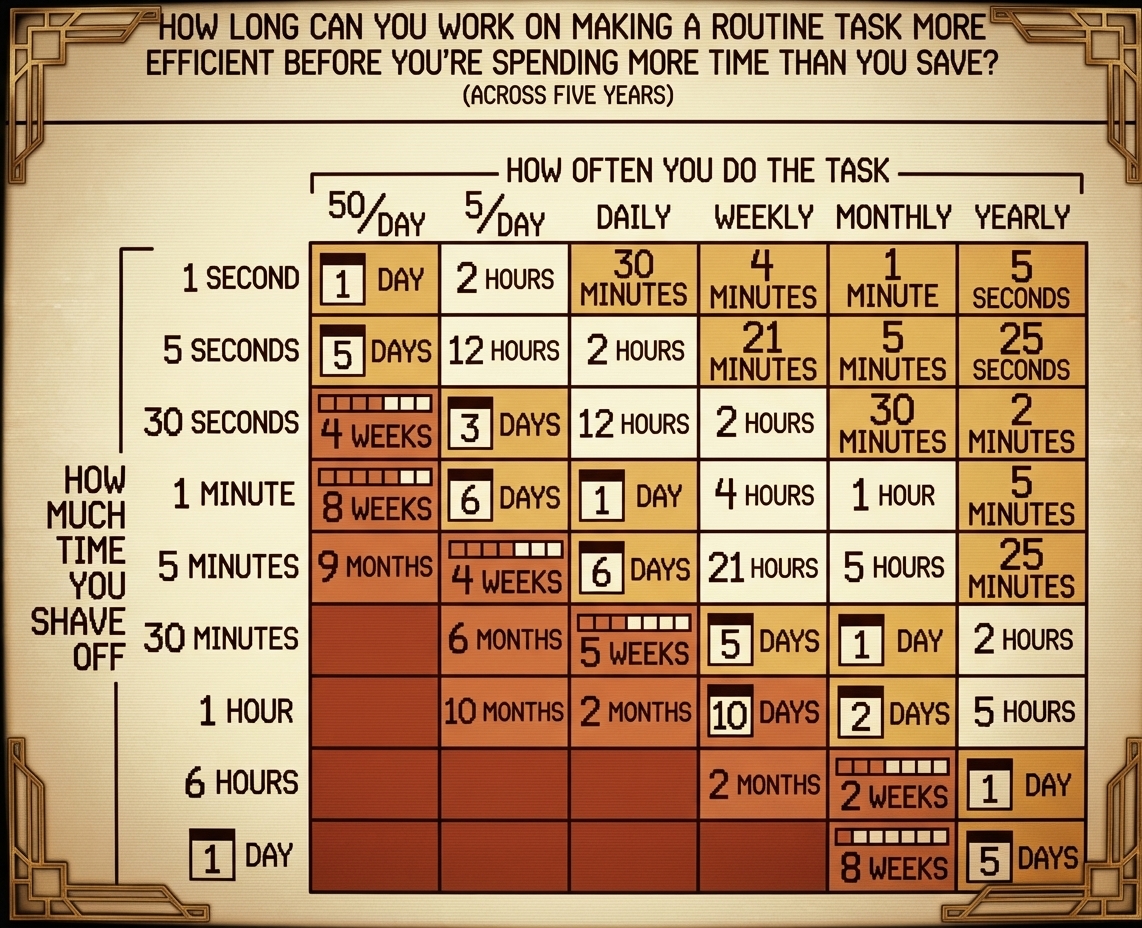
Quinn Slack recently pointed out the same idea applied to AI coding: the time you invest in your harness pays off across every future session.